이 논문에서는 자율주행(Autonomous Driving)에서의 보행자(pedestrian)와 차량(vehicle)의 움직임과 동선(trajectory)을 예측(motion prediction)하기 위한 다양한 방법들을 분류하여 설명하고 있다.
저자들은 세 가지 분류 체계(taxonomy)로 예측 방법들을 분류하고 있다.
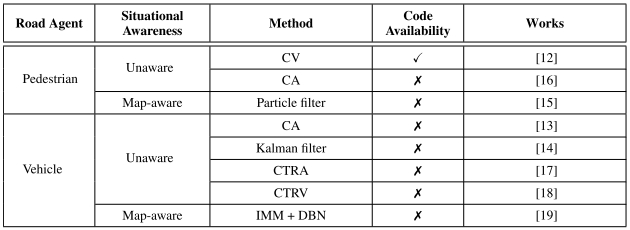
도로 사용자(Road Users)를 둘로 나누면 보행자와 이동체(자동차)로 나눌 수 있다.
자율주행차(Autonomous Vehicle, 이하 ‘AV’)는 보행자의 의도를 이해하는 것이 중요하다. 이들이 길을 건널지 말지, 어디로 얼마나 움직일지 알아야 경로를 계획할 수 있다. 보행자는 교통 규칙(traffic rules) 뿐만 아니라 약식(informal)의 사회적 규칙이나 비언어적 표현을 사용한다. 이러한 비공식적 사회적 규범들을 이해하면 보행자를 보다 안전하게 지키며 자율주행을 행할 수 있다.
자동차의 움직임을 예측하는 것은 교통 규칙과 도로 지형에 영향을 받는다. 자동차의 움직임은 교통 규칙 뿐만 아니라 다른 주변의 자동차나 도로 사용자들에 의해 영향을 받으므로, 그들의 미래 움직임과 궤적(trajectory)을 예측하는 것은 복잡하다. 따라서 주변의 모든 자동차를 고려해 VOI(Vehicle of Interest)의 사용 가능한 미래 궤적을 예측해야 한다.
앞서 밝혔듯, 세 가지 분류 체계를 사용해 motion prediction을 분류한다. 단, 분류가 이렇다는 것이지 이들이 각 카테고리만으로 한정된다는 말은 아니다.
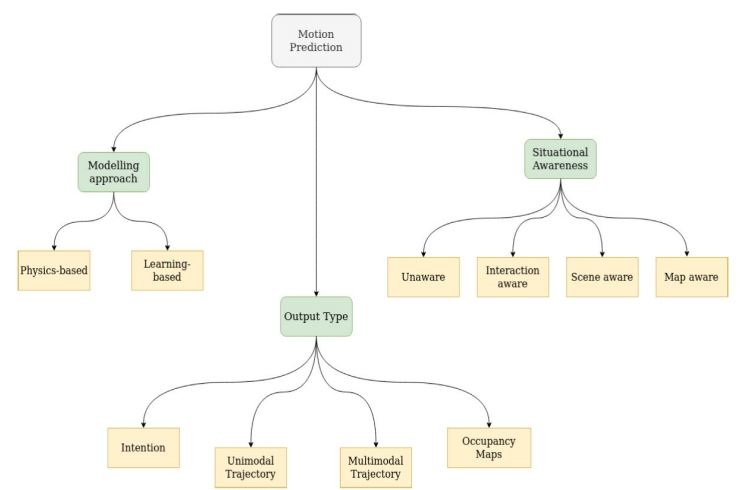
Modelling을 기준으로 분류하는 방식은 motion prediction 방법을 physics-based approach와 learning-based approach로 나눈다.
Physics-based 방식들은 물리학 법칙에 기반해 움직임과 물리학의 식을 사용해 행위자(agent)의 미래 움직임(forward motion)을 파악한다. 여기엔 뉴턴의 법칙을 기반으로 동역학·운동학 모델이 있다.
동역학적 모델(Dynamic model)은 움직임에 영향을 주는 모든 힘(forces)을 고려한다. 해당 모델은 매우 복잡한데, 예를 들자면 타이어에 가해지는 힘과 운전자의 판단이 이동체의 엔진과 트랜스미션에 미치는 영향 등을 모두 고려하기 때문이다. 저자는 궤적을 예측할 때는 이러한 복잡한 동역학적 모델이 크게 연관이 있어 보이진 않는다고 밝혔다.
반면 운동학적 모델(Kinematic model)은 움직임을 움직임에 관한 파라미터들의 수학적 관계의 관점에서 표현한다. 사용이 단순하기 때문에 궤적 추정에 매우 빈번하게 사용된다.
운동학적 모델의 예시가 몇 가지 있다.
CV(constant velocity) 모델은 객체의 최근 상대적 움직임이 미래의 궤적을 만들어낸다는 가정을 한다. t 시간에 이동체의 top-down 좌표를 x, y라 하면 위치 p는 $p = (x^t, y^t)$로 표현할 수 있으며, 궤적을 예측하기 위한 가장 최근의 정보는 $\triangle p = p^t - p^{t-1}$로 표현한다.
또 다른 예로 CA(constant acceleration) 모델은 최근의 가속도의 상대적 변화를 객체의 미래 궤적을 결정하는 인자로 가정한다. 칼만필터와 CA를 함께 사용하기도 하고, paricle filter나 road semantic graph를 사용하기도 한다.
칼만 필터와 CTRV(constant turn rate and velocity) 혹은 CTRA(constant turn rate and acceleration)를 사용해 비선형성을 표현하기도 하고, IMMTP(Interatctive multiple trajectory prediction)에 UKF(Unscented Kalman Filter), DBN(Dynamic Bayesian Network)를 이용하는 예도 있다. 칼만 필터는 불확실성을 가우시안 노이즈(Gaussian noise)의 형태로 표현하며, 칼만 필터의 예측 단계의 출력으로서 동역학적 혹은 운동학적 모델을 사용해 위치 추정값을 내놓는다. 이 과정 후엔 센서 측정값을 기반으로 예측값이 업데이트된다.
필터를 사용하는 문제는, 불확실성의 unimodal 표현이다. 이는 복잡한 이동체의 궤적을 포착하지 못한다. 불확실성을 표현하는 더 나은 방법은 가우시안의 혼합 사용(mixture of Gaussians)이다.
Learning-based 방식들은 데이터와 통계로부터 학습을 진행하고, 이 학습된 모델로부터 움직임 패턴(motion pattern)을 인지한다. 여기서 말하는 데이터에는 이동체의 이전 경로와 환경의 bird-eye view(BEV), 센서 데이터 등이 포함된다. Physics-based 모델이 움직임의 저수준 속성(low-level properties)에 제한되고 움직임의 장기 의존성(long term dependencies)를 추정하지 못함에 반해, Learning-based 모델은 장기 의존성을 포착하고 외부 요인에 의한 변화를 포함할 수 있다. Learning-based 방식은 sequential과 non-sequnetial 모델로 다시 나뉜다.
Sequential model은 agent의 움직임을 예측을 수행할 때 그들의 상태의 history를 이용한다. 마르코프 추정(Markovian assumption)(행위자의 미래 움직임은 현재 상태에 따름)을 사용한다는 점, 그리고 one step 예측기(predictor)라는 점에선 Physics-based 모델과 유사하다. 다만 Sequential model은 motion model 대신 통계적 관찰(statistical observation)으로부터의 학습 함수(learning function)를 사용한다는 점에선 차이가 있다.
대표적인 예시는 Dynamic Bayesian Network(DBN)이다. 임시적(temporal) 업데이트를 하는 베이지안 신경망이다. 이 확률적 모델은 시간에 걸쳐서(unrolled) 관찰할 때 유용하다. DBN은 마르코프 속성을 갖고 있다.
최근에는 복잡한 장기 독립성을 포착하기 위해 연구가 진행되고 있다. 시계열을 예측하는 신경망을 사용하며, 자연어 처리와 같은 Sequence modelling으로부터 적용된다. 순환신경망(RNN, Recurrent Neural Networks)나 LSTM(Long Short-term Memory) 신경망이 최근 궤적을 예측하는 데 인기를 얻고 있다. naviagting에 있어 사람이 사용하는 사회적 행동방식(behaviour)과 상식적 규칙을 고려할 수 있다. 네트워크를 통해 VOI의 장면(scene)에서 feature을 추출한다.
뿐만 아니라 GAN(Generative Adversarial Networks)도 사용될 수 있다.
Non-Sequential model은 데이터와 데이터의 분포를 학습하되, 마르코프 추정과 같은 제약이 없다. 과거 프레임의 피드백에 의존하지 않으면서 완전한 궤적을 예측한다.
대표적인 예시는 clustering trajectories model이다. 클러스터링의 접근 방식에서는 클러스터의 형태에서 global한 움직임 패턴을 이해하고, 각 행위자의 local 움직임 패턴에 이를 부과한다. 부분적인 궤적에 기반해 전체적 궤적을 학습한다.
또는 CNN을 이용하기도 한다. 합성곱층과 학습 가중치들을 이용해 이미지로부터 특징을 추출하고, 이 특징을 완전연결층에 전달해 궤적이나 occupancy, transition map 등의 출력을 얻는다. 특정 연구에서는 CNN이 LSTM보다 장기 의존성 측면에서 좋은 성능을 보이기도 했다.
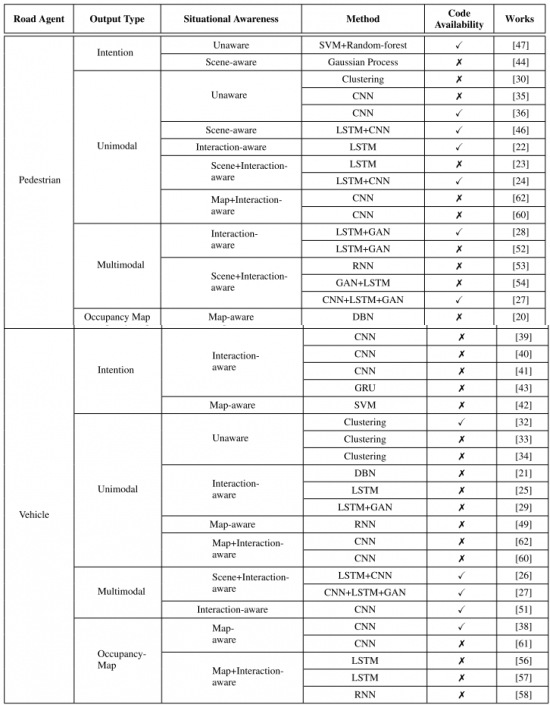
보행자나 이동체의 의도를 예측하는 것은 미래에 장면이 어떻게 변할 지에 대한 통찰을 줄 수 있다.
이동체의 경우 앞으로 하려는 동작(manoeuvre)에 기반해 의도를 분류할 수 있어, 앞선 차를 따라갈 것인지, 왼쪽이나 오른쪽으로 이동할 것인지 등으로 나눌 수 있다. 이러한 행동은 지금 이동체가 사거리에 있는지 혹은 고속도로에 있는지 등의 현 상황(scene situation)에 달려 있다.
보행자의 경우, 의도 예측(intent prediction)은 그들의 동작이 아니라 보행자가 미래에 취할 행동이나 상태를 포함한다. 1초 뒤 혹은 그 뒤에 보행자가 어떤 포즈, 경로, 상태를 취할지 예측하거나 분류한다.
보행자와 이동체의 행동을 표현하는 더 정확한 방법은, 단순히 의도(intension)를 사용하는 것보다는 모델로부터 경로의 출력(trajectory output)을 얻는 것이다. Unimodal Trajectory는 불연속적인(discrete) 궤적 포인트를 사용해 하나의 궤적을 출력한다. 이 불연속적 궤적 포인트들은 spline이나 베지어 곡선(Bezier curves) 등을 통해 연속적으로 변환될 수 있다.
이동체의 경우, 도로에서의 행동은 복합한 동작들의 집합으로 정의되는데, Unimodal Trajectory의 출력은 더 나아가 의도된 동작(intended manoeuvre)에 궤적이 독립적인지/의존적인지로서 정의될 수 있다.
의도한 동작에 독립적인 궤적은 가능한(possible) 동작을 고려 하지 않는 Unimodal Trajectory이다. 이 방식은, 특정 시간에 같은 가능성(chance)를 갖는 두 개의 동작이 있다면 이들을 평균하려는 경향이 있다. 이는 자칫 충돌로 이어질 수도 있다. 반면, 의도한 동작에 의존적인 혹은 제한되는 궤적은 더 안전하고 의미 있는 예측을 한다. 다만 이 방식의 문제점은, 새 궤적을 탐색하는 가능성이 오직 하나의 궤적에만 제한된다는 점이다. 보행자를 보행자로서 적용하지 않고, 보행자의 동작(사회적 규칙에 영향을 받는)을 분류하지 않는다.
Unimodal trajectory의 확장이 Multimodal Trajectory이다. 한 개의 궤적이 아니라 여러 개의 궤적을 출력으로 얻는다. VOI는 다수의 동작이나 동작의 분포를 고를 수 있고, 이러한 분포에 대한 정보로 예측 알고리즘을 더욱 강인(robust)하게 만들거나 식별되지 않은(unidentified) 궤적 출력으로 가지 않도록 한다. Multimodal Trajectory에서는 각 동작이나 모드에서 unimodel 궤적을 얻는데, 전과 마찬가지로 모델은 동작에 의존적이거나 독립적이다. 동작에 의존적이라 함은 확률 분포가 동작의 집합에 대해 유한하다는 뜻이고, 동작에 독립적이라 함은 출력의 개수가 정해져있다(fixed number)는 뜻이다. 제한되지 않은 multimodal Trajectory 출력의 문제는, 주로 한 모드로 수렴한다는 점이다. 이를 ‘mode collapse problem’이라고 한다. 손실 함수를 수정해 모델이 출력을 다양하게 탐색하게 하는 등으로 해결한다.
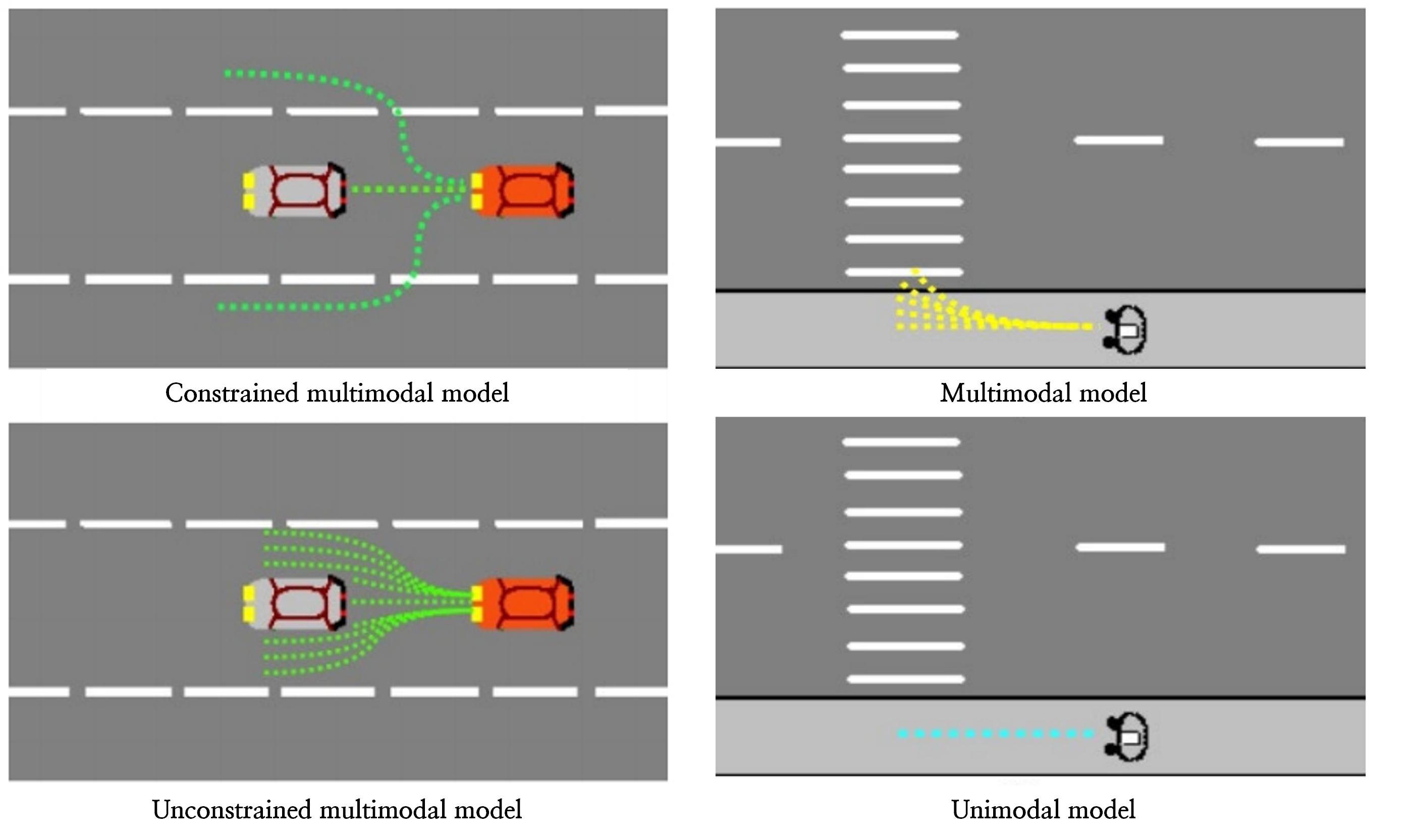
의도(intension)이나 하나의 궤적(single trajectory, unimodal 방식)으로만 예측하는 것보다는 Multimodal Trajectory의 출력을 이용하는 것이 AV가 움직임을 계획(motion planning)을 하는 데 더 안전하다.
Occupancy Maps 혹은 Image Raster(점 방식)에서는 BEV로 미래 특정 시점에서의 상황을 예측한다.
Occupancy Maps는 주로 특정 장면에서의 정적 장애물의 위치(’occupancy’를 의역)를 보여준다고 알려져 있으나, dynamic occupancy grid map도 가능하다.
top-down 격자에 점으로 색칠해 표현하거나, 움직임 추정 모델의 출력인 이동체의 궤적을 표시할 수도 있고, 어떤 장애물을 피하려 하는지에 대한 semantic segmentation 정보도 담을 수 있다.
Situational Awareness는 도로 행위자의 미래 궤적에 영향을 줄 수 있는 환경과 동적 장애물들의 정보에 대응된다. 이 정보는 도로 행위자의 좌표나 top-down raster, road semantics 등 수치적 데이터로 행동 모델에 입력된다. Situational Awareness를 4가지로 다시 분류할 수 있다.
행동 예측 방식들은 각각의 행위자들에게서 얻은 정보만으로 그들의 행동을 예측하는데, 이는 주변의 정적 혹은 동적 환경을 알지 못하고(unaware) 주변 요소들로부터의 영향을 받아 일어날 수 있는 행동의 변화를 포함하지 못한다. physics-based 방식 대부분이 unaware 모델에 포함된다. CV, CA 모델이나 CTRA, CTRV와 함께 칼만 필터를 사용한 모델이 그러하다.
Interaction Aware 행동 예측 모델은 행위자들의 미래 움직임을 예측하기 앞서 가이드라인으로서 주변 행위자들의 정보를 이용한다.
환경의 문맥(context)에 대응해 인식을 수행한다. 사거리나 로터리, 고속도로 등 운전하는 환경이 차이가 있음을 인식하는 것이다. 특정 장면(scene)의 특징(feature)은 이미지 등의 센싱 데이터의 형태로 모델에 전달된다.
scene aware 모델의 확장으로서, 문맥적 단서(contextual cue)로서 HD 맵 등의 지도의 semantic 정보를 사용한다. 대신 이 경우는 scene aware 모델보다는 날씨나 기타 환경에 대한 정보는 부족하다.