ROS를 가동하며 다양한 상황에 직면하는데, 그 중 아래 일곱 가지의 문제를 생각해볼 수 있다. 현상을 파악해보고 그 원인을 알아보며, 해결책을 찾아 적용해본다. 1~5번은 주어진 과제였고, 6~7번은 추가적으로 생각해본 문제들이다.
토픽을 주고 받는 과정에서 Publisher 혹은 Subscriber의 데이터 누락이 발생할 수 있다. rosrun으로 직접 파일을 가동하면 Subscriber 노드를 먼저 가동하고 그 다음에 Publisher를 가동시킴으로써 선후 문제를 해결할 수는 있지만, 노드 수가 많아질 경우에 매우 복잡하고, roslaunch의 편리함을 포기할 순 없을 것 같다.
일단 현상을 한 번 살펴본다. 기존의 방법대로 평범하게 퍼블리셔와 서브스크라이버, 런치 파일을 구현해본다.
🌳 sr_serial.launch

🌳 sender_serial.py

🌳 receiver_serial.py
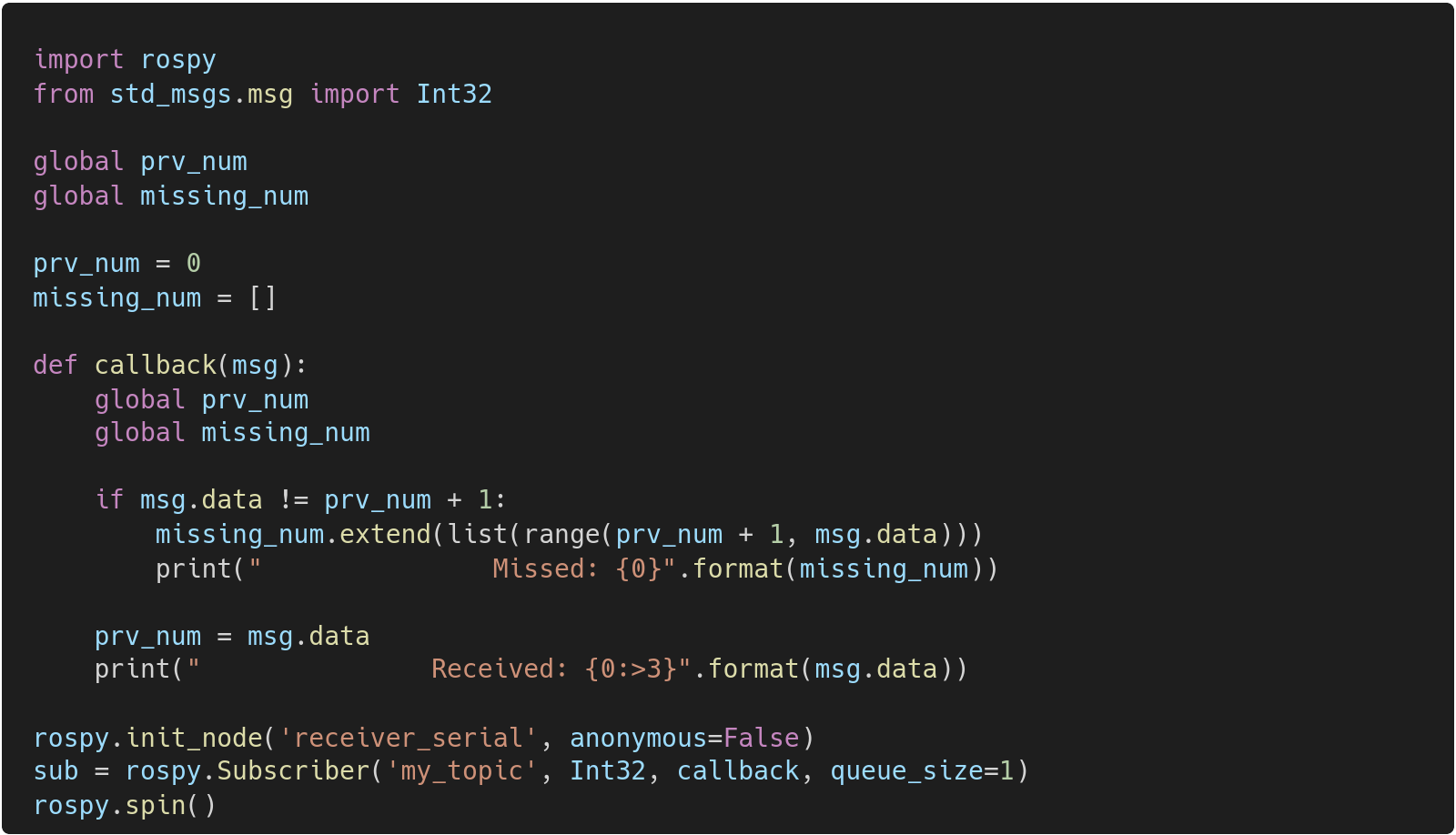
사실 receiver_serial.py에 전역변수(global)를 썼는데, 전역변수의 선언을 개인적으로 좋아하는 편이 아니다. 하지만 저 짧은 코드를 쓰는데 클래스를 선언하기엔 과하다 싶어 전역변수를 쓰는 쪽을 택했다.
이제 실행 결과를 살펴보자.

퍼블리셔는 분명 1을 보냈으나, Receiver는 첫 번째 데이터를 받지 못하고 그 다음 데이터부터 받아들이기 시작했다. 누락이 발생한 것이다.
가장 주요한 원인은 서브스크라이버가 아직 준비되지 않았는데 퍼블리셔가 먼저 토픽을 전송하고 있었다는 점에 있다. 이는 아래 1-3에서의 해결 방법으로 처리될 수 있다.
조금 논제에 벗어난 이야기이긴 하지만, 중간에 데이터가 누락되는 경우도 있는데, 이는 큐 사이즈에 관련하여 이야기할 수 있으며, 3번에서 더 다룰 예정이다.
이를 해결하기 위해 Publisher 객체의 get_num_connections() 메서드를 활용할 수 있다. 해당 메서드는 퍼블리셔 객체와 연결된 커넥션의 개수를 반환한다. 위 문제를 예로 들자면 서브스크라이브 노드가 연결되지 않았다면 0을, 연결되었다면 1을 반환하는 것이다.
따라서 아래 사진처럼 코드를 수정해본다. 퍼블리시에 커넥트된 개수를 조사하여 연결된 것이 없다면, 즉 아직 서브스크라이브가 켜지지 않았다면그 때까지 기다리며 while 문 안에 머무른다. 따라서 publish() 까지 가지 않고 대기하게 된다.
🌳 sender_serial.py 의 수정

실행 결과는 아래와 같다. 1부터 잘 받아오는 것을 확인할 수 있다.

해당 코드는 중간에 여러 개의 숫자가 누락되어도 이를 탐지하게 해두었다. receiver_serial.py 코드의 callback() 함수에 일부러 rospy.sleep(2)를 넣고 지연시켜보면 아래처럼 우르르 데이터가 손실되는 것을 볼 수 있다.
콜백 함수의 지연, 데이터 손실, 큐 사이즈의 문제는 아래쪽 순서에서 더 다룰 것이다.

특정 시간 안에 얼마나 많은 데이터를 얼마만큼의 속도로 보내고 받을 수 있을지 측정하고자 한다. 또한 데이터 크기에 따른 전송 속도는 어떻게 달라지는지 역시 알고 싶다. 이를 알아내기 위해 수신과 송신 모두 약 1분의 시간동안 줄곧 데이터를 주기만 하고 받기만 하며 속도를 측정했다. 데이터의 크기는 Mbyte의 단위로 나타냈고, 속도는 1초당 데이터의 MB 크기인 Mbps로 한다.
launch 파일은 위와 거의 유사하니 생략한다.
🌳 sender_speed.py
코드를 살펴보면, 다양한 크기의 퍼블리시 데이터 사이즈를 선언해두었다. 문자 1개당 1byte이므로 데이터의 크기를 곱해줌으로써 한 토픽에 들어갈 데이터의 크기를 정해둘 수 있다. 또한 퍼블리시를 할 때 퍼블리시한 시각도 함께 적어 보냈다.

🌳 receiver_speed.py
수신 측에서는 송신한 시각과 현재 시각을 빼 데이터의 수신 시간을 구했다.

실행 결과를 보자. 순서대로 1, 5, 10, 20, 50MByte를 전송했을 때의 결과이다.



1분 전체의 속도가 아닌, 각 토픽 당 속도를 보면 1MB일 때는 3~4Mbps 였던 것이 점차 4~5, 5~6, 8~9Mbps로 늘더니 50MB를 전송할 때는 9~12Mbps로 크게 늘었다. 적게 보낼 수록 더 자주 보낼 수는 있으나 단위 시간 당 데이터의 크기인 속도는 그리 높지 못하다.
아래는 1분 동안의 전체 데이터에 대해 속도를 구한 것을 송신과 수신에 따라 그래프로 그려본 것이다.

전송 시간을 1분으로 짧게 잡아 테스트해서인지 50Mbyte 단위의 테스트에서 송신 쪽이 급격하게 이상한 값이 나왔다. 더 정확한 결과를 얻기 위해서는 측정 시간을 늘려 반복 측정을 해야 할 것이다.
대강의 추세만 보면, 한 번 보내는 데이터의 크기가 늘어남에 따라 전송은 더 빨리 일어나고 수신은 더 느리게 일어난다.
수신 쪽에서는 수신하는 데이터의 크기가 클수록 수신 속도가 전반적으로 줄어들었다. 데이터의 크기가 클수록 송신한 뒤 수신까지 이어지는 시간이 오래 걸리기 때문인 것으로 보인다. 실제로 같은 시간동안 받는 데이터의 수 자체가 급격히 줄어드는 것을 볼 수 있었다.
송신 쪽에서는 송신하는 데이터의 크기가 클수록 송신 속도가 증가하는 추세를 보였다. 송신의 경우 보내는 데 시간은 얼마 걸리지 않으나 한 번에 큰 데이터를 보내기 때문에 초당 데이터 양이 크다. 하여 송신 속도가 증가하는 것으로 보인다.
데이터의 크기를 측정한다고 했는데, 사실상 보내고 받은 데이터는 딱 1MB, 5MB, …이지 않을 것이다. 당장 데이터 뒤에 시각까지 함께 적어 보냈으니 문자열의 크기는 그만큼 더 길어졌을 것이다. 개인적인 호기심에는 데이터를 다시 메시지가 포장하여 토픽으로 보내고 있으므로 토픽, 혹은 토픽 속 메시지의 크기를 계측해야 하는 것이 아닌가 하는 의문이 들었다.
receiver_speed.py속 데이터 사이즈를 아래와 같은 두 가지 케이스로 살펴보았다. sys.getsizeof()는 인자로 전달한 객체의 크기를 반환하는 함수이다.

sys.getsizeof(msg)로 메시지 자체의 크기를 측정했을 때는 msg.data의 크기와 상관없이 64byte였다. 또한 sys.getsizeof(msg.data)로 메시지 속 데이터의 크기는 빈 데이터는 37byte였고, 한 문자 당 1byte 씩 증가했다. 가장 작았던 계측이 1MB였으므로, 37byte는 사실상 그리 유의미한 차이를 가져다 줄만큼의 영향은 아닌 것으로 보인다.

퍼블리셔는 토픽을 보내고 서브스크라이버는 받는다. 서브스크라이버는 받은 토픽을 callback 함수에서 처리한다. 그러나 만약 callback 함수에서 다음 토픽이 올 때까지 이전 토픽을 다 처리하지 못한다면 어떻게 될까? 처리하는 도중에 들어온 데이터는 누락이 될까, 아니면 어딘가에 쌓이게 될까? 쌓인다면 얼마나 쌓이게 될까?
이를 파악하기 위하여 퍼블리셔는 1초에 1000번의 퍼블리시를 하도록 구현해놓았으며, 서브스크라이버의 callback 함수 안에 일부러 오랜 시간이 걸리도록 조치를 해놓고 추세를 지켜보았다.
역시 launch 파일은 1과 거의 유사하므로 넘어가겠다.
🌳 sender_overflow.py
rate를 1000으로 설정하여 1초에 1000번의 토픽을 전송한다.

🌳 receiver_overflow.py
callback() 함수 안에 rospy.sleep()을 일부러 넣어 의도적으로 처리를 지연시켰다. 해당 코드가 실행되는 동안엔 callback() 함수는 처리하고 있는 토픽에 머물러 있다. 퍼블리셔가 퍼블리시하는 값은 1씩 증가하므로, 이전에 받았던 값과 지금 처리하고 있는 값이 1 차이가 나지 않는다면 데이터 누락이다. 얼마나 누락이 되었는지를 찾는 부분도 추가해두었다.

실행 결과는 다음과 같다.

‘cnt’는 누락된 토픽의 개수(한 번에 1씩 증가해 보내므로 1 당 1개)를 나타내는데, 그 추세를 부면 callback() 함수가 한 번 호출될 때마다 약 3000개 내외로 잃어버림을 알 수 있다. 또는 새로 들어오는 값들의 증가폭을 봐도 같다. 즉, 함수가 처리하지 못한 토픽들은 허공에 휘발되어 버린다.
Subscriber 객체를 선언할 때 인자로 queue_size를 설정할 수 있다. 위 코드는 그 값을 1로 했을 때이다. 이 값을 늘려보면 어떻게 될까? 필자는 저 값을 5로 늘려보았다. 결과는 아래와 같다.

처음 실행을 제외하고는 하나를 받고 그 뒤에 4개가 더 차례대로 값이 들어온다. 분명 새로 값을 찍을 때마다, 즉 callback() 함수가 새로 돌 때마다 지연 시간이 있었음에도 누락되지 않은 것이다. queue_size를 5로 설정해두었기 때문이다.
Subscriber가 설정된 크기만큼 데이터를 저장해두고 하나씩 앞에서부터(queue의 작동대로) 꺼내 callback() 함수를 돌린다. 이렇게 되면 중간에 누락도 어느 정도 보상할 수 있을 것이다. 그러나 저장된 값을 처리하는 동안에는 역시나 그 뒤의 누락이 생긴다. 숫자의 증감을 보면 3032~3036을 처리한 뒤에는 바로 11227이다. 8190개를 잃어버린 것이다. 앞서서는 한 번에 약 3000개씩 잃어버렸다면 그 크기가 매우 증가한 것이다.
예전 데이터를 꺼내봐야 한다면 모르겠지만, 금방금방 갱신할 데이터라면 차라리 처리하지 못한 데이터는 무시하고 최신 걸로 업데이트하는 것이 좋을 듯하다. 센서를 예로 들자면, 굳이 이미 지나간 값이 된 예전의 센싱 값을 불러오는 것은 무용지물이란 것이다.
rospy.Rate()는 Hz 단위로 주기를 설정한다. n을 주었다면 (1/n)초의 주기인 것이다. Rate(5)라면 0.2초가 한 주기가 된다. 이 한 ‘주기’를 타임 슬롯이라고 한다. 그렇다면 Rate(5)로 했을 때는 1초에 0.2초 크기의 타임 슬롯이 5개가 생긴다.

퍼블리시를 할 때 rospy.Rate()와 rospy.sleep()은 함께 다니는데, sleep()은 해당 주기의 크기를 지켜주는 역할을 한다. 가령 주기가 1초인데 처리에 걸린 시간은 0.2초라면, 1초의 나머지인 0.8초는 sleep()을 이용해 쉰다. 다르게 말하면 sleep()은 타임 슬롯의 크기를 알고 있다.
보통 퍼블리시의 예제들을 보면 주기적으로 토픽을 발송한다. 그러나 이런 주기적 발송 중 타임슬롯을 넘어가면 어떻게 될까?

위 그림처럼 여러 가지 상황이 발생할 수 있다. Case1이 원하는 상황이지만 처리 시간이 타임슬롯을 넘어가는 경우에는 Case2, 3, 혹은 그 다른 양상으로 동작할 것이다. Case2는 타임슬롯이 다 넘어가더라도 모든 데이터들을 앞의 것이 끝나는 대로 전송하고, Case3는 타임슬롯이 넘어가면 일단 다음 슬롯까지 쉬고 주기에 맞게 다시 전송한다. 이 외에도 수많은 경우의 수들을 생각해볼 수 있겠다.
이를 알아보기 위해 다양한 주기, 다양한 데이터 전송 횟수를 가정하여 테스트를 진행하였다.
🌳 sender_timeslot.py
사용자의 입력을 두 개 받는다. r은 rate를 나타내며 타임 슬롯 하나의 크기(= 1/r초)를 결정한다. num은 해당 타임슬롯 당 퍼블리시의 개수를 나타낸다. 한 타임슬롯 당 수행해야 할 퍼블리시는 do_job() 함수에 구현하였다. num 만큼의 퍼블리시를 한다. publish()와 sleep()에 걸리는 시각을 각각 계측하고 둘을 합쳐 한 슬롯 당 시간을 계측한다. 마지막에는 전체 슬롯 당의 소요 시간을 계산한다.

🌳 receiver_timeslot.py

실행 결과는 다음과 같다. 1초당 10개, 100개, 1000개를 보내는 경우로 나누고, 그 안에서 다시 Rate와 Num의 경우의 수를 나누었다.



조금 더 보기 편하도록 그래프로도 나타내었다.

초당 보내는 데이터의 수가 같다고 하더라도 num, 즉 (1/r)초당 보내야 하는 개수가 많아지면 오버플로우가 발생해 그만큼 슬롯의 시간도 급격히 늘어난다. 가령 1초당 10개를 보내야 한다면 한 슬롯에 최대 0.2초가 걸려야 하는데 그 이상이 소요되는 것이다. 위 사진에서도 볼 수 있듯이 오버플로우가 발생하지 않을 때는 sleep()에 걸리는 시간이 꽤 길다. 그러나 오버 플로우가 발생하면 거의 쉬지 않고 바로 다음으로 넘어간다.
또한 오버플로우가 발생한다면, 즉 타임슬롯을 넘어간다면 중간에 건너 뛰지는 않고 타임 슬롯을 넘어가는 한이 있어도 꾸역꾸역 다 보내긴 보낸다. 위 그림에서 본 Case2에 해당한다.
추가 고찰 : 위 말이 맞는지 데이터 보낼 건 다 보내는지 받는 쪽에서 체크해볼 수도 있겠다.
여러 노드들이 협업하는 경우에, 한 노드가 실행되고 난 뒤에야 다른 노드가 실행되도록, 노드의 순차적 실행을 구현해보고자 한다. 1번에서 보았듯이 roslaunch로는 노드의 가동 순서를 정할 수 없다. 다른 방법으로 노드를 순차적으로 실행해보고자 한다.
First부터 Fourth 노드는 Receiver에게 토픽을 전송하는데, Second는 First가 전송을 시작한 뒤에야, Third는 Second가 전송을 한 뒤에야 시작하는 식으로 작동하도록 한다.
🌳 sr_order.launch

🌳 first.py
퍼블리시를 하는 쪽은 본인이 퍼블리시를 시작했다는 의미로 플래그 토픽을 하나 더 보낸다. first는 가장 먼저 시행되므로 서브스크라이브 없이 퍼블리시만 두 개 한다.

🌳 second.py (third.py도 유사하게 작성)
이전 노드가 값을 퍼블리시 하면서 flag 토픽도 보내면 can_start 플래그를 True로 만들고, 해당 값이 True여야만 publish 하도록 구현한다. 따라서 second는 first가 받은 토픽을 받아 flag를 변경한 뒤에야 퍼블리시를 시작한다. third도 같은 방식으로 작동한다.

🌳 fourth.py
fourth는 이전인 third만 끝나기만 하면 보내기만 하면 되므로 플래그용 토픽을 따로 보내지는 않는다.

🌳 receiver.py

실행 결과는 아래와 같으며 rqt 그래프도 함께 나타냈다. 차례대로 순서대로 퍼블리시 및 서브스크라이브 되고 있음을 알 수 있다.


여러 토픽을 서브스크라이브하는 노드 있다고 하자. 이때 서브스크라이버가 각 토픽을 모두 받지 못한 상황에서 어떠한 작업을 하면 사용해야 하는 값이 누락되어 에러가 발생한다. 이런 경우 모든 토픽을 받은 뒤에야만 작업을 시작하도록 구현해보려고 한다.
각자의 토픽을 보내는 퍼블리셔로 3개의 노드(sender1, 2, 3)가 있고, 그들을 받는 하나의 서브스크라이버 노드를 있다. sender2와 3은 각각 3초와 5초 뒤에 노드를 만들어서 노드 커넥션 자체를 딜레이시켰다.
🌳 additional1.launch

🌳 sender_topic1.py

🌳 sender_topic2.py

🌳 sender_topic3.py

🌳 receiver_topics.py
1번에서 퍼블리셔의 get_num_connections() 함수로 서브스크라이버가 연결되었을 때 퍼블리시를 하도록 구현하였다면, 여기서는 Subscriber의 메서드로서 get_num_connections()를 이용하였다. 받아야 하는 토픽이 세 개, 즉 노드가 3개가 연결되어야 하므로, 각 토픽을 받는 서브스크라이버의 get_num_connections() 합이 3이어야 모두 연결된 것이다. 각각의 callback 함수에서 해당 커넥션 개수를 살핀 뒤 작동하게 하였다.

실행 결과는 아래와 같다.

따라서 Publish 객체 뿐만 아니라 Subscribe 객체도 get_num_connections() 함수를 사용할 수 있다. GPS, IMU, LiDAR 센서들의 값이 아직 들어오지 않았는데 자율주행 알고리즘을 시작해버리면, 잘못된 초기값이 설정되거나 아예 값이 없어 연산이 불가능해 에러를 발생시키곤 한다. 이런 식으로 처리하면 그런 상황을 줄일 수 있을 것으로 예상된다.
퍼블리셔가 더이상 토픽을 전송하지 않는데, 만약 서브스크라이버는 rospy.spin() 등으로 계속 기다리고 있는 상황을 가정해본다. 이럴 경우, 일정 시간동안 받아야할 토픽이 오지 않는다면 자동으로 종료하게 하고자 한다.
🌳 sender_timer.py
퍼블리셔는 특정 시간 동안만 퍼블리시를 하고 종료되게 구현하였다.

🌳 receiver_timer.py
서브스크라이버에서는 타이머를 걸었다. callback 함수에서 마지막으로 토픽을 받았던 시간을 기록해둔 뒤, while 문을 돌면서 토픽을 받지 않은 경과 시간을 체크한다. 여기서는 5초를 기준으로, 받지 않은지 5초가 지났다면 return 하여 노드를 종료시킨다.

아래는 실행 결과이다.

이를 활용하면 특정 토픽을 전송해야 하는 퍼블리셔가 문제가 생겼거나, 제대로 주고 받지 못할 경우를 탐지할 수 있을 것 같다.


